

We built Matchbook to help you raise more money. To us, that means reaching people who actually want to hear from your campaign or organization.
Too often, fundraisers in our ecosystem are left to use and re-use the same stale lists of donors that get passed around between campaigns, vendors, and PACs. With each cycle of re-use, those lists return less money, generate more spam reports, and further alienate our strongest supporters.
That’s why we built a donor lookalike engine. This tool takes a list of your existing donors, matches them to our extensive voter database, figures out what’s unique about them, and finds totally new people who share their traits. You could take a list of 1,000 existing donors and turn it into 20,000 brand new donor prospects.
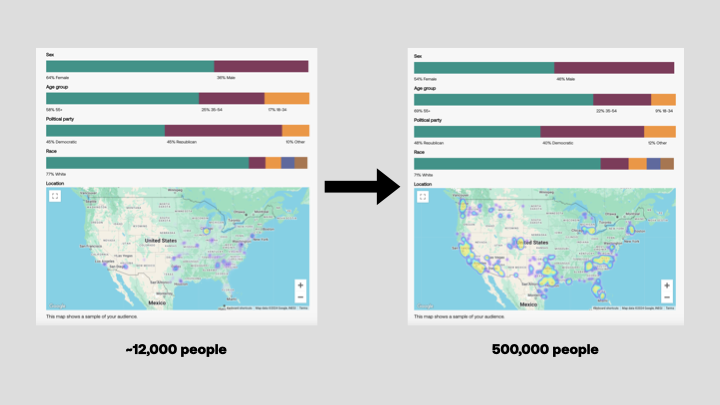
You can then take your lookalike audience to a digital advertising platform like Meta, send them direct mail, or reach them with TCPA-compliant text messages using a platform like Switchboard. Our content evaluation tools can even help you figure out the best way to engage with these new donor prospects!
But before you take advantage of this tool, you might be curious how it works. Here’s how we do it:
Step 1: Voter file processing and feature engineering
Our process begins by preparing our voter file for matching (in order to connect it to your list) and modeling (in order to identify patterns that make the people on your list special). The person-level features we engineer include (but are not limited to):
- Demographic traits: Age, gender, race, and ethnicity
- Socioeconomic traits: Education level, occupation, homeownership
- Geography: Location, population density, neighborhood-level traits
- Behaviors: Voting history, consumer purchases, online activity patterns
- Contact information: Phone numbers, email addresses, mobile device IDs, IP addresses
By compiling this dataset from many different data sources, we enable the highest possible match rates and a nuanced understanding of what defines your core audience.
Step 2: Matching your list to our voter file
Whether you have detailed information about each person on your list, or you just have emails, we use a thorough probabilistic matching algorithm to identify the most likely matches for each person on your list. We then see which approach resulted in the highest probability of a match for each record, and deliver the resulting matches. Depending on how much data you provide, match rates could range from ~25% (for just emails) to ~95% (for names + dates of birth + ZIP codes).
Step 3: Building dozens of prospective models
Since no specific pre-programed model architecture or feature set is likely to perfectly fit each audience, we train dozens of unique models using a range of approaches. First, we use VSURF to generate a variety of feature sets. We then use those features in a grid search across 80,640 unique deep learning architectures with unique combinations of values across 9 different hyperparameters. Each resulting model offers a unique perspective on what defines your source audience, capturing different patterns and interactions within the data.
Step 4: Selection of the best model
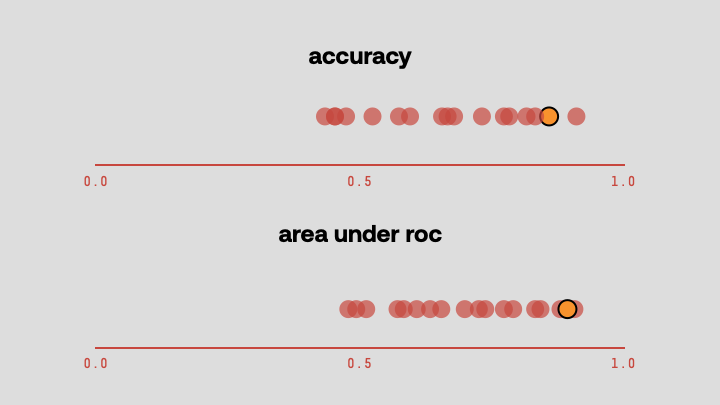
To identify the optimal model, we then evaluate each prospect using a standard set of evaluation metrics, including but not limited to:
- Accuracy: Evaluating the model’s overall correctness when estimating that a person would be in your target population
- Area under the ROC curve: Assessing the model’s ability to distinguish between people who would be in your source list versus those who would not
- Gain captured by the model: Evaluating the model’s effectiveness at distinguishing between those most likely and least likely to be in your target population
- Precision and recall: Measuring the model’s ability to identify true positives while minimizing false positives
We then select the model that performs best across all of these metrics. The model we select may not be the best-performing on any specific metric, but it should be the best when weighing all the metrics together.
Step 5: Scoring the entire voter file for proximity
With the optimal model chosen, we then use it to score every individual in the voter file, producing a probability that the person would have been in your source list if they had been given the opportunity and then ranking each person by that probability, from highest to lowest.
If you added additional demographic, socioeconomic, behavioral, or demographic filters when creating your lookalike audience, we will only rank people who meet those criteria.
Step 6: Delivering your audience
Finally, we use those rankings to return the number of individuals you requested who most resemble your original audience. In Matchbook, you can elect to export a range of data about your audience – including email addresses, phone numbers, mailing addresses, and personal traits.
***
At Indigo, we think it’s important to make the relationship between organizations and their audiences more authentic. That starts with finding and building strong relationships with your people – not generic donor targets. We’re hoping that our lookalike audiences can be a big step in that direction.
